MM-Spatial: Exploring 3D Spatial Understanding in Multimodal LLMs
ICCV 2025
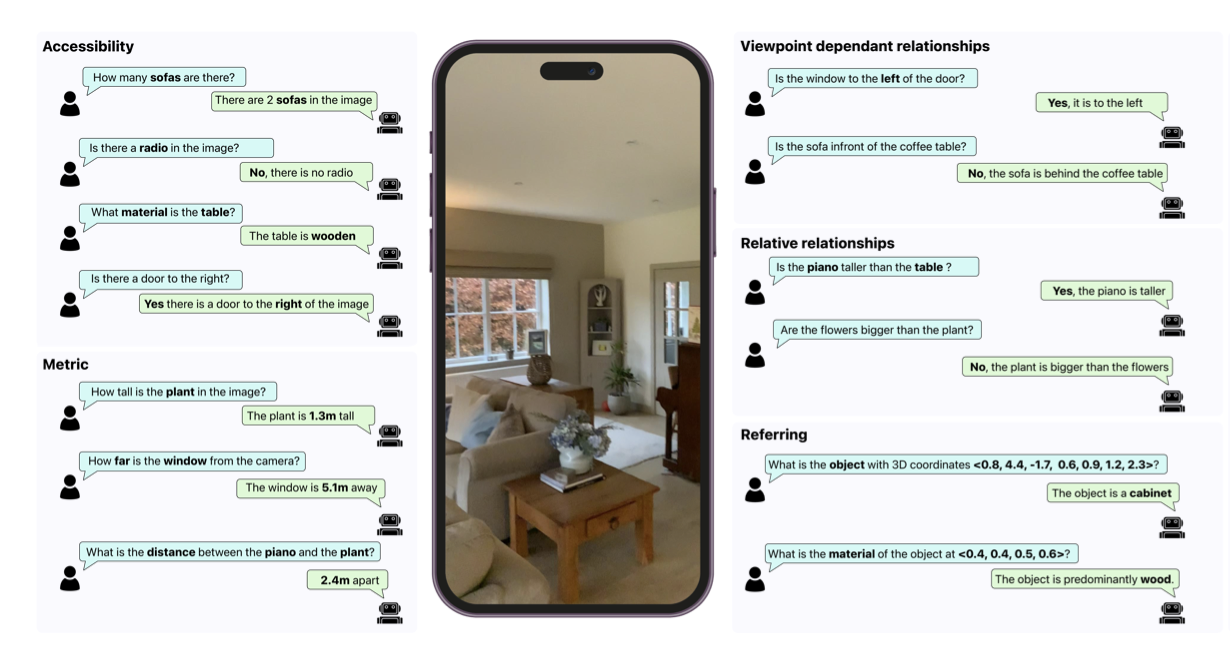
Building on the Cubify Anything CA-1M, we generate VQA question pairs using an automated pipeline. We show reformatting high-quality 3D data in this way allows us to achieve SoTA results on many 3D spatial reasoning benchmarks.